
The Web Project Book’s “Implementing Backend”: Putting Sanity.io to the test
I have been following the work of Deane Barker (aka Gadgetopia) for a while. And although I often find myself disagreeing with him, it's hard to get away from that much of the work on CMS he has been involved is pretty darn insightful. One of his projects is “The Web Project Guide” that he writes together with Corey Vilhauer. I recently got aware of the chapter “implementing the backend functionality”, which in this case mostly deals with the content management system.
So, early disclaimer: I work for Sanity.io, where we're making what we call the platform for structured content. It replaces your CMS, but it also gives you more power and flexibility when it comes to how to interact with that content, not just in terms of distribution. It lets you treat content as data. That's the key.
So, of course, read this as content marketing if you want, but I hope you can get something out of it if you're interested in content management. And yeah, if Deane can be strategic director over at Episerver while writing this guide (he started it before taking on this position, I believe), I think it's OK for me to see their writing through the lens of Sanity.
This post makes most sense if you have at least scrolled through their chapter beforehand, but I'll try my best to give enough context to make sense. This also why I follow the same structure in terms of headings. With that out of the way, let's jump into it!
Most CMSs can publish content in some form out-of-the-box, but they have to be...persuaded to do it in a way that fulfills your requirements.
I went ahead and initiated a new project with the “clean templates”, which comes with no content types at all. So little persuasion needed, in fact, Sanity.io is designed not to have to be persuaded into being what you want, but exactly the opposite, it's built to be configured and customized to precisely what you need (you can give yourself a head start though).
Model implementation
The model implementation is your content model working inside your chosen CMS.
With Sanity.io you get an open-source application that functions as the CMS in most cases. You do model implementation by describing schemas in simple JavaScript objects. This is somewhat different compared to most CMSs where you do it with forms in a graphical interface. It may seem more difficult, but it lets developers and people with some JavaScript skills to version control schemas, and have a short way to do more advanced stuff like custom field validation and code-based generation of schemas. It also makes the distance to customizing input components much shorter.
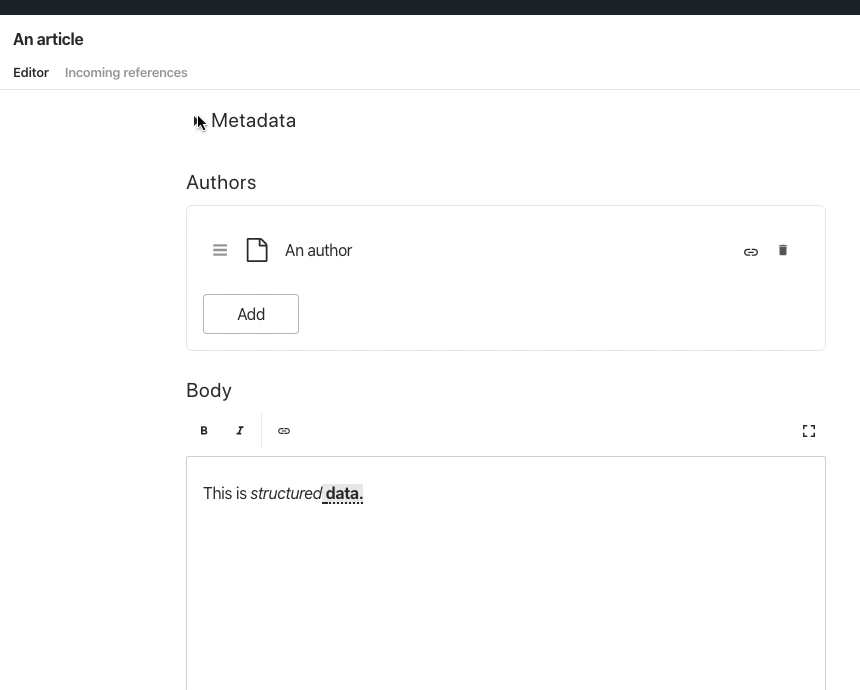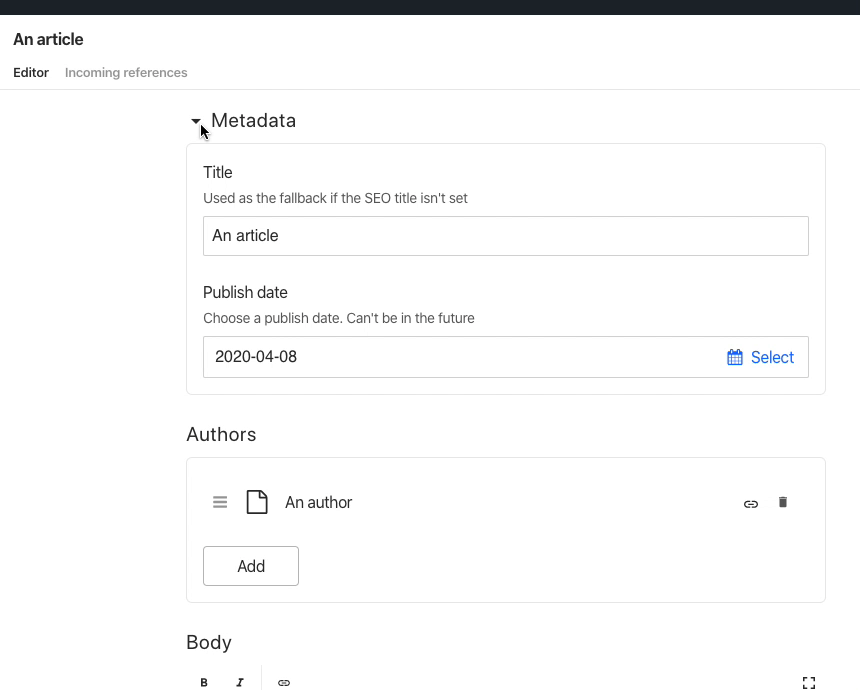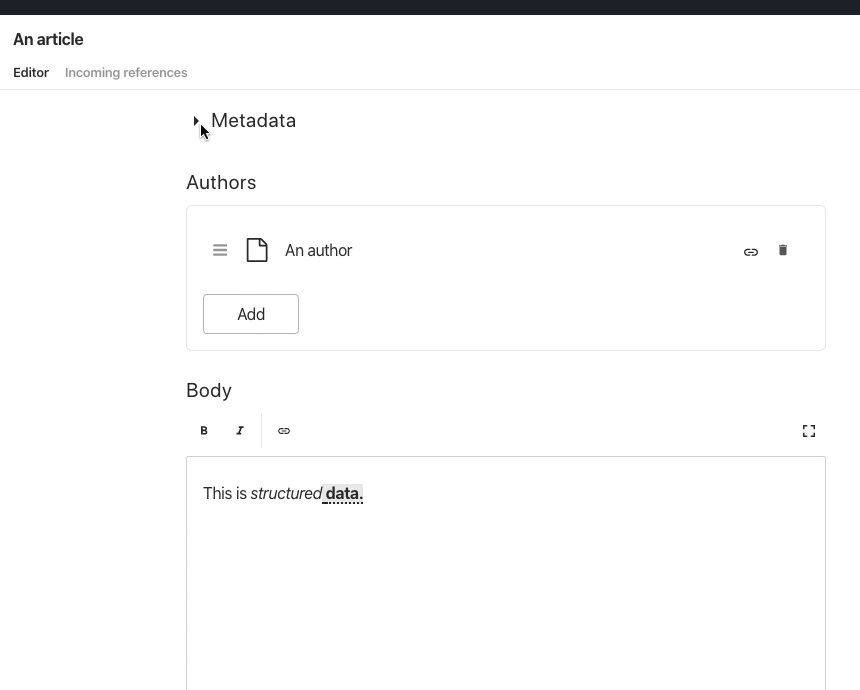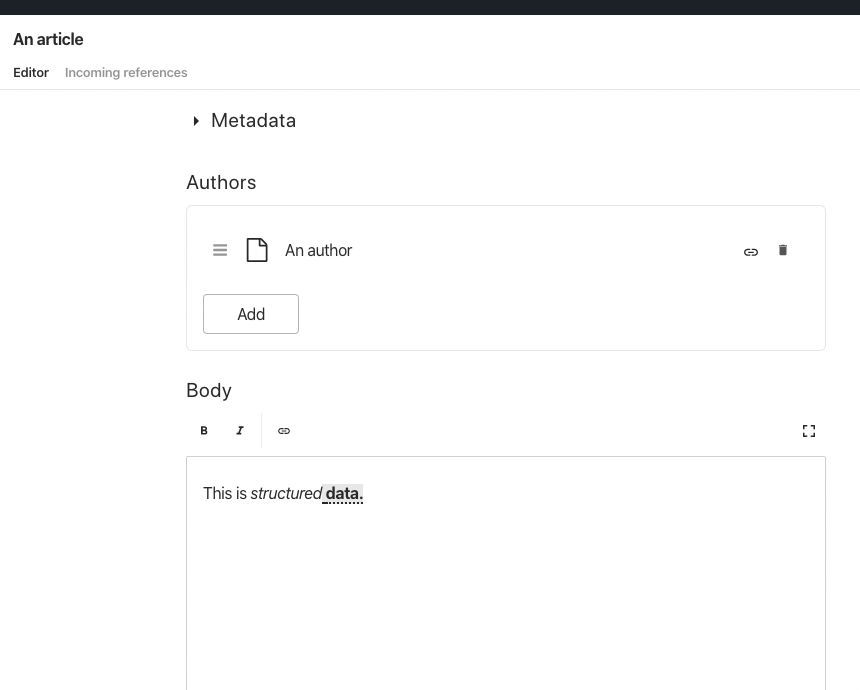
The guide mentions that a model is a combination Types, Attributes, and Validation Rules, and uses an “Article” (type) with “Title” and "Publication Date" (attributes), and “minimum length” (validation) as an example. If you run npm i -g @sanity/cli && sanity init and go through the steps, you'll be ready to make the content model within a couple of minutes. Here's how you make the minimal article example with Sanity:
// article.jsexport default {name: 'article',type: 'document',title: 'Article',fields: [{name: 'title',type: 'string',title: 'Title',validation: Rule => Rule.min(10).warning('The title should be longer')},{name: 'publishedAt',type: 'datetime',title: 'Publish date',description: 'Choose a date for when the article should be published'}]}
When you run the studio (it's a single page application built with React) this code will generate a user interface that looks like this:
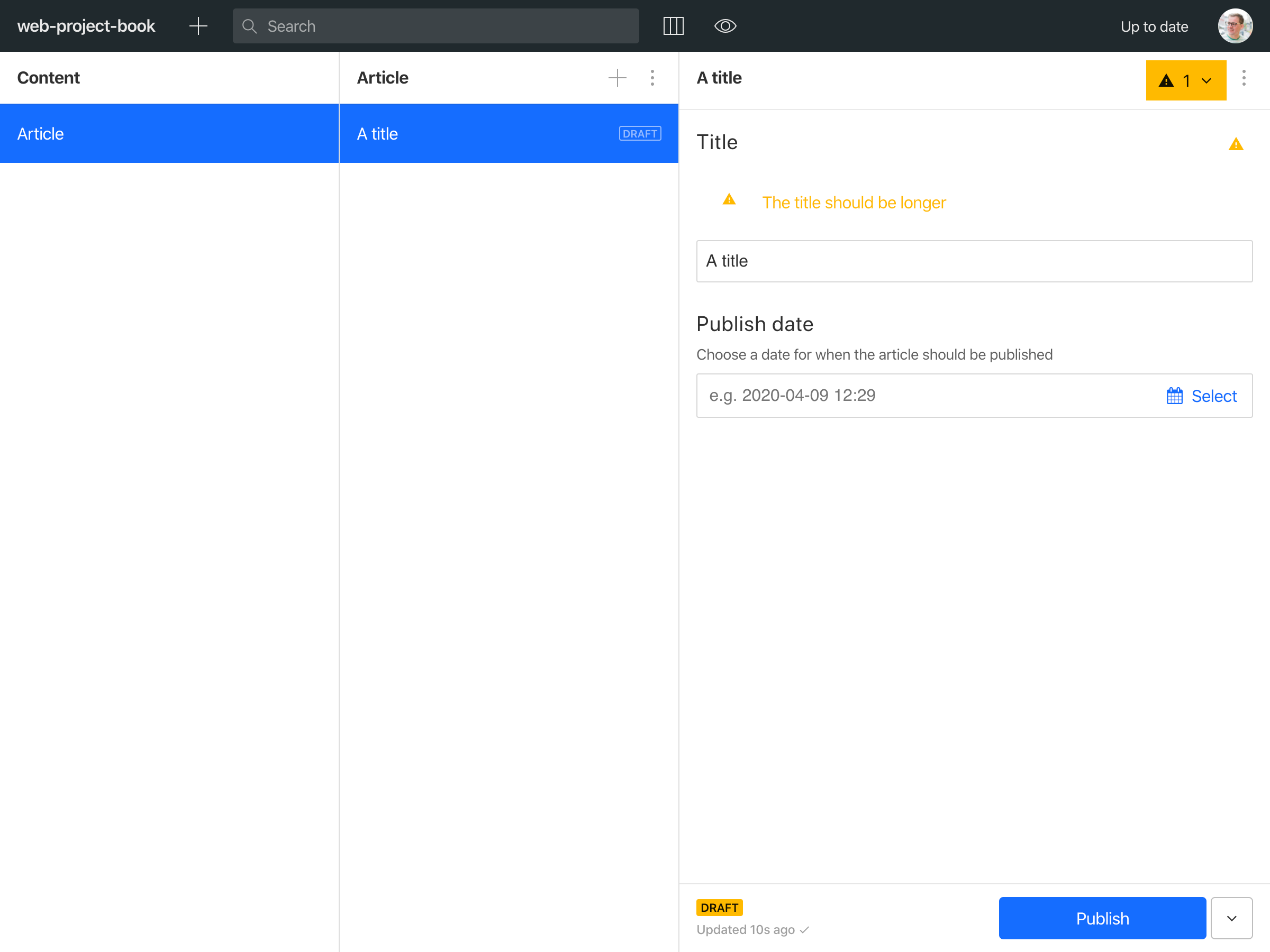
So far, so good. Where it gets interesting is when it comes to content model limitations. Sanity.io is built for structured content, so we have gone far to make it as flexible as possible.
Limitations?
However, sometimes you just can’t wrap a CMS around your model requirements.
Here the authors come with two examples:
- The model supports linking the Article object to an Author object, but it doesn't let you go in the other direction, i.e. the link isn't bi-directional.
- Your model requires a Meeting object to have sub-objects for Topics. Each Topic is also a content object.
Bi-directionality
Let's add an author type and a new field to the article which is an array of references to the author type (because you want multi-author support, don't you?):
// author.jsexport default {name: 'author',type: 'document',title: 'Author',fields: [{name: 'name',type: 'string',title: 'Author',},],}
export default {name: 'article',type: 'document',title: 'Article',fields: [// the other fields,{name: 'authors',type: 'array',title: 'Authors',of: [{type: 'reference',to: [{ type: 'author' }],},],},],}
When using the reference attribute/field, Sanity will index those references bi-directionally. So if you wanted to query all authors with their articles although the field is set in the article object, it can be done like this with GROQ using joins (actual example):
*[_type == "author"]{name,"posts": *[_type == "article" && references(^._id)]{title}}
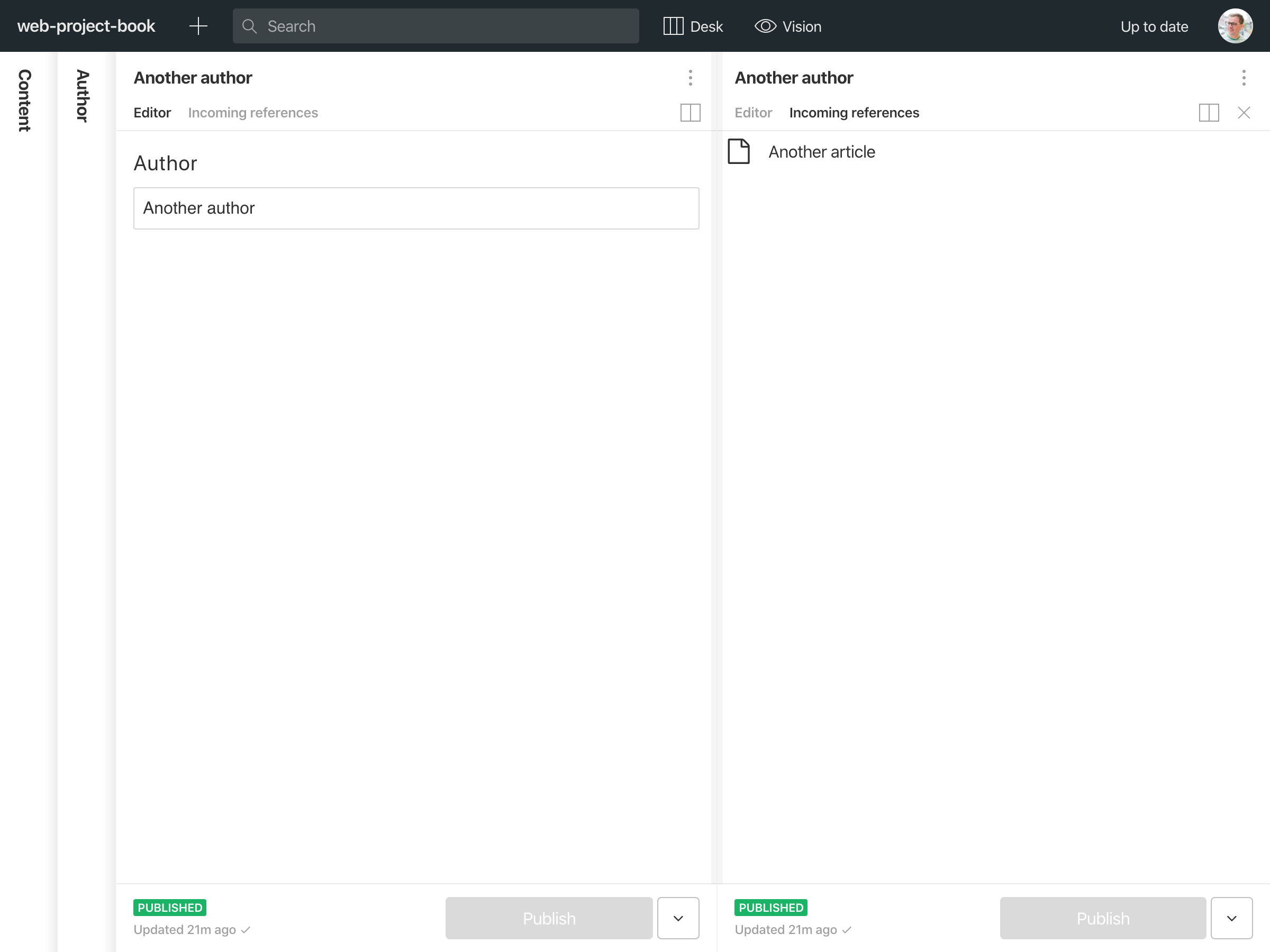
This query can also be baked into the Sanity Studio using split panes to show “incoming references”. This is a minimal example (and of course, you can use the same logic to show “related” documents by pretty much any logic):
// deskStructure.jsimport React, { Fragment } from 'react';import S from '@sanity/desk-tool/structure-builder';import QueryContainer from 'part:@sanity/base/query-container';import Spinner from 'part:@sanity/components/loading/spinner';import Preview from 'part:@sanity/base/preview';import schema from 'part:@sanity/base/schema';const Incoming = ({ document }) => (<QueryContainerquery="*[references($id)]"params={{ id: document.displayed._id }}>{({ result, loading }) =>loading ? (<Spinner center message="Loading items…" />) : (result && (<div>{result.documents.map(document => (<Fragment key={document._id}><Preview value={document} type={schema.get(document._type)} /></Fragment>))}</div>))}</QueryContainer>);export const getDefaultDocumentNode = () =>S.document().views([S.view.form(),S.view.component(Incoming).title('Incoming references'),]);export default S.defaults();
This will produce this interface, and by the way, it's real-time, so if someone adds this author to another article, it will appear in the right list without requiring reloading.
Nested structures
The second limitation has to do with nested structures (parent-child). Personally, I tend to avoid putting too much hierarchy into content models, and I suspect it often comes from “sitemap” and “nested menu” thinking where you structure content to make navigation. I prefer representing navigation as a separate content structure with references because that lets us more quickly iterate on navigation structures, but also have different content trees for different presentation layers and purposes. But I digress, let's look at the example:
Your model requires a Meeting object to have sub-objects for Topics. Each Topic is also a content object. To do this, you need to connect a Topic to a Meeting in a parent-child model. However, your CMS doesn’t have a content tree that would allow this, nor does it allow nested objects. You can link a Topic to a Meeting, but someone else could link another Meeting to the same Topic (not allowed by the model), and it doesn’t stop the Meeting from being deleted and “orphaning” a bunch of Topics (also verboten).
There are mainly two approaches to this with Sanity, you can either just embed the topic object model in the meeting model because the schema allows for nested objects. You would still be able to query for only topics, and you will never have this orphanage or multiple meetings tied to the same topic, which in this case is unwanted. Here is a simple example:
// topic.jsexport default {name: 'topic',type: 'object',title: 'Meeting topic',fields: [{name: 'name',type: 'string',title: 'Topic name',},{name: 'description',type: 'text',title: 'Description',},],}
// meeting.jsexport default {name: 'meeting',type: 'document',title: 'Meeting',fields: [{name: 'date',type: 'date',title: 'Meeting date',},{name: 'topic',type: 'topic',title: 'Meeting topic',},]}
Notice how I have described topic as an object type here, and how I refer to this type in the meeting schema. The interface for this will look like this:
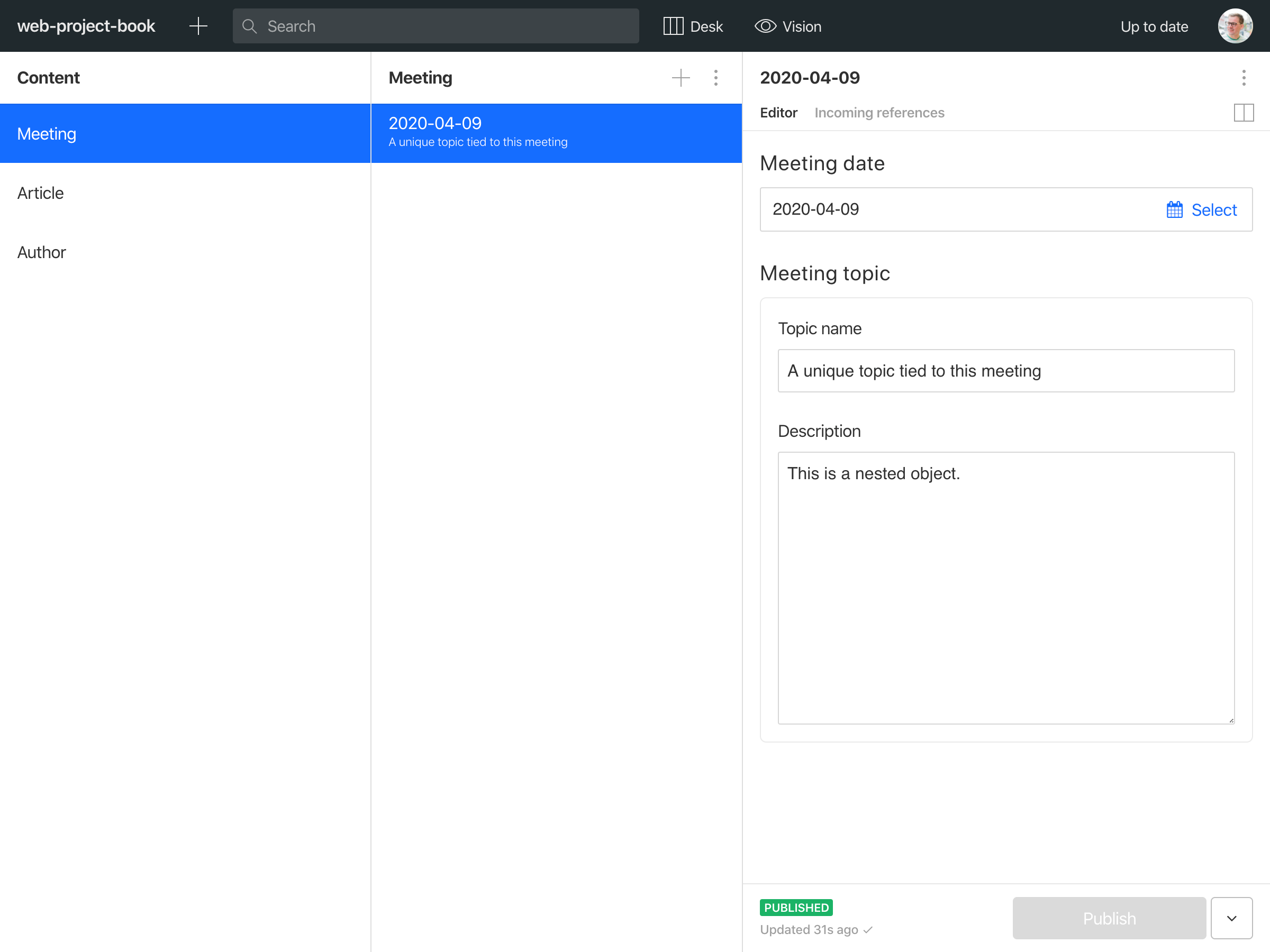
And the data structure will end up like this:
{"_createdAt": "2020-04-09T11:21:22Z","_id": "d9996973-58aa-44be-8a8a-c24c7df61b6e","_rev": "lwxf4peCy8NTOg4fhvBuIK","_type": "meeting","_updatedAt": "2020-04-09T11:21:22Z","date": "2020-04-09","topic": {"_type": "topic","description": "This is a nested object.","name": "A unique topic tied to this meeting"}}
And if I wanted to query all meetings and return just the topics in my dataset, I could do it with this GROQ query: *[_type == "meeting"].topic.
Now, let's make this a bit more interesting, and say that we wanted to implement topic as a dedicated document type, and use references to tie them to meetings. If we want to avoid orphan topics, we need to put the reference on the topic side. If a topic has a reference to a meeting, you can't delete that meeting without removing either the topic or the reference first. Granted, the UI for this flow can (and will get) a bit smoother. But here's how to do it:
// topic.jsexport default {name: 'topic',type: 'document',title: 'Meeting topic',fields: [{name: 'name',type: 'string',title: 'Topic name',},{name: 'description',type: 'text',title: 'Description',},{name: 'meeting',type: 'reference',title: 'Meeting',to: [{ type: 'meeting' }],},],}
This will produce this interface:
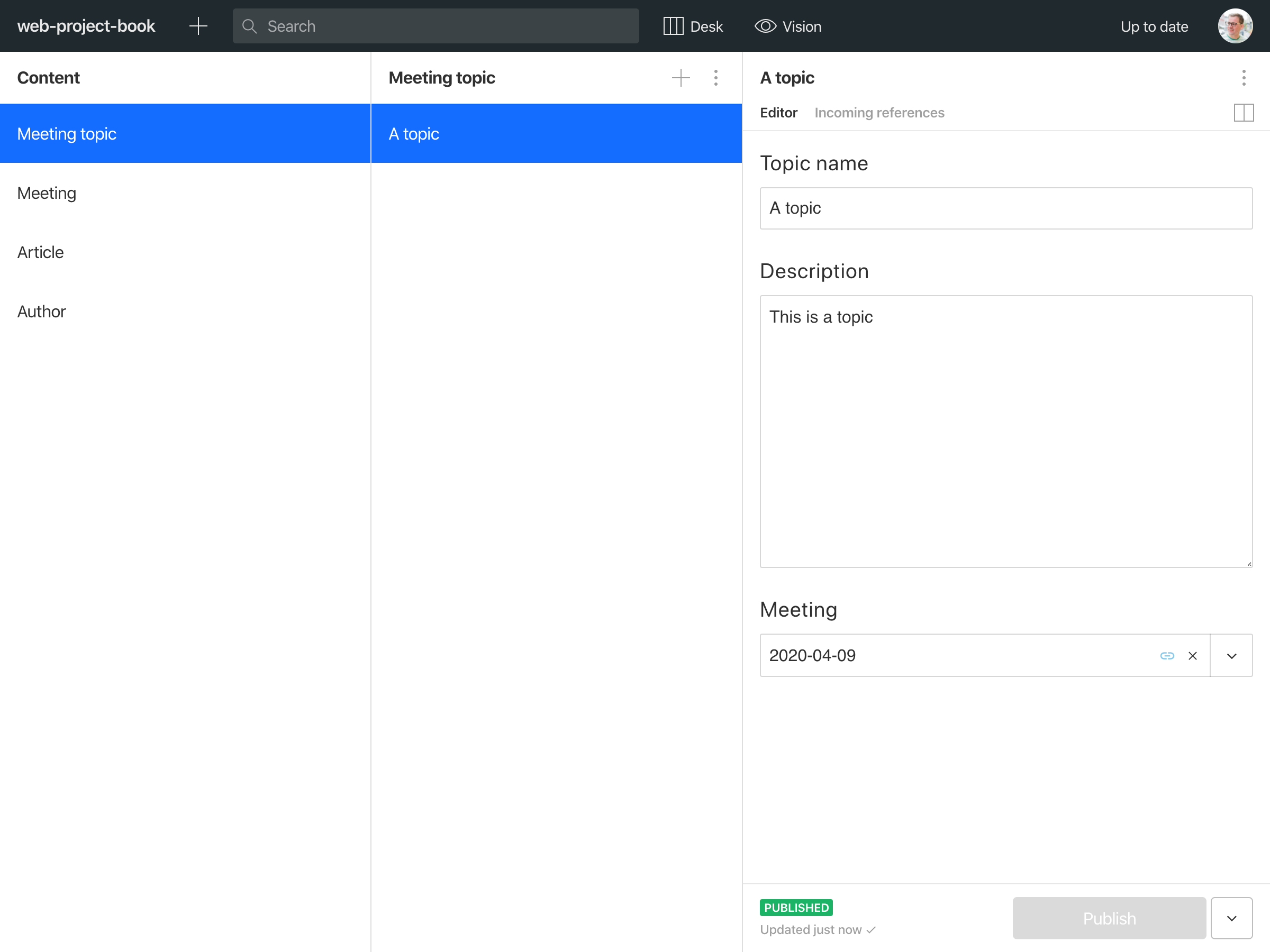
And if you now try to delete the referenced meeting, you'll get this warning:
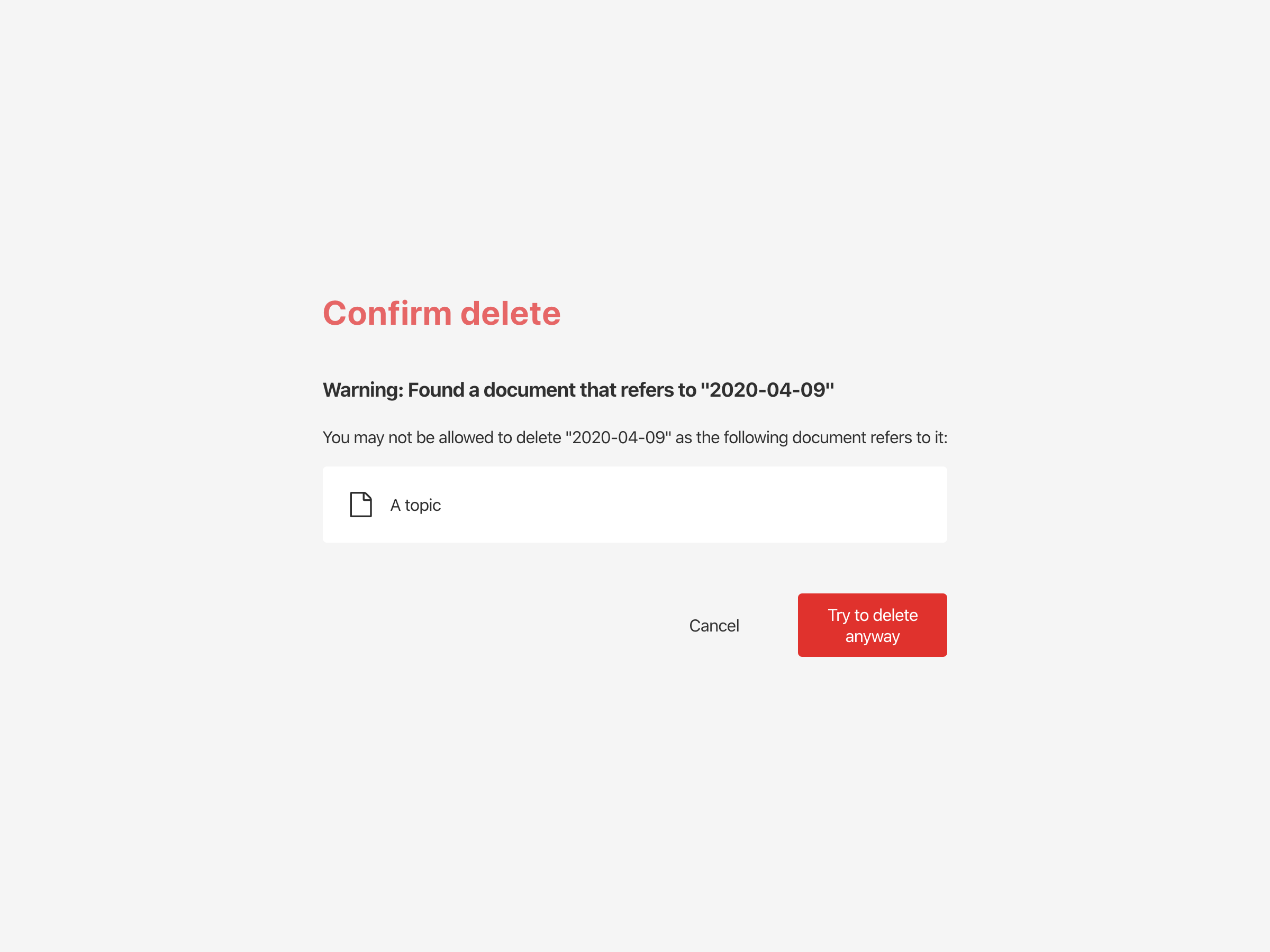
Sidenote: You can define references as _weak: true if you explicitly don't want this integrity check.
Editorial Experience
The authors discuss the concepts of Data Coercion and Data Validation, in other words, making sure that it's easy to let editors put in content in the correct format, and validate the content if it's possible to enter it incorrectly. The first example is adding a publish date field for an article, where it doesn't have a time stamp, and the date shouldn't be in the future. Here's how to do exactly that with Sanity:
{name: 'publishedAt',type: 'date',title: 'Publish date',description: "Choose a publish date. Can't be in the future",validation: Rule =>Rule.custom(date =>date =< new Date().toISOString().split('T')[0] ||`This shouldn't be in the future`),}
Sidenote: The validation property also supports promises and any logic you can express in JavaScript, which means that you can validate fields via APIs and whatnot. All fields come with common validation rules out-of-the-box.
The next example is rich text editing, but with constraints on formatting. Sanity’s rich text editor is configurable and extendable. It also saves the text into a structured and syntax agnostic format called Portable Text, so that even if you had formatting that you didn't want in your presentation layer, it is pretty easy to ignore it in the implementation. A rich text field with only bold (or strong) italics (or emphasis) and linking looks like this:
// simpleRichText.jsexport default {name: 'simpleRichText',type: 'array',title: 'Body',of: [{type: 'block',styles: [],lists: [],marks: {decorators: [{ title: 'Strong', value: 'strong' },{ title: 'Emphasis', value: 'em' }]}}]}
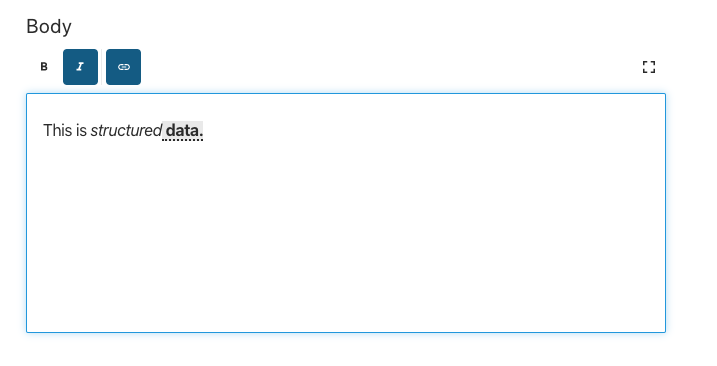
Moving on, adding a description to the title field explaining it's used as the fall back SEO title, is also pretty effortless. And of course, you can have fields called title with different descriptions throughout the CMS:
{name: 'title',type: 'string',title: 'Title',description: `Used as the fallback if the SEO title isn't set`,validation: Rule =>Rule.min(10).warning('The title should be longer'),}

The last example is affordances for grouping fields into tabs or sets to lessen the cognitive load. Sanity comes with fieldsets out of the box, and somebody has made a plugin that expresses these as tabs.
// article.jsexport default {name: 'article',type: 'document',title: 'Article',fieldsets: [{name: 'meta',title: 'Metadata',options: { collapsed: true, collapsible: true },},],fields: [// the fields]}
All in all, it seems like Sanity meets all the examples given for content modelling and the examples mentioned. And we've just scraped the top of the ice-berg of what's possible in terms of catering to an awesome editoral experience. Because, it's true as the authors write:
Cater to your editors. Implement your content model at a level that allows the CMS to help them. The happier they are, the better your content will be, and the longer your CMS implementation will last.
The Sanity Studio comes with a lot of field types out of the box, and lets you make your own custom input components if you have special data coercion needs, and as we touched on, you can do field validation with promises and JavaScript.
Aggregations
Since the underlying data for Sanity.io are JSON documents, that can be queried and join on pretty much any key/value the need to explictly author aggregation descreases (want an implementation to group any document that starts with "F" in it's title field (if it has one), no problem: *[defined(title) && title match "F*"].
But there are perfectly sound reasons to make explicit aggregations of content, so let's go through the different types mentioned by the authors.
A Content Tree
A very common pattern is a “tree” of content, where you have a "root" object with a hierarchy of descendants below it. Every object is a child of another object, and might have one or more children of its own.
As I previously mentioned, I'm not a big a fan of structure content deeply into a hierarchy. Soon enough editors are required to be “hiearchy janitors”, and there almost always comes a point where you want to break out of that hiearchy or do it differently. But sometimes you actually need to put content into parent-child-like structures where they also have order. For those times, I tend to make another document type with fields to express hierarchies.
A practical example is how the documentation and its table of contents is done on sanity.io/docs. The articles is a flat list of the article type, while the menu is made as a document type called toc (as in Table of Contents):
// toc.jsconst tocSection = {name: 'toc.section',type: 'object',title: 'Section',fields: [{type: 'reference',name: 'target',title: 'Target article',to: [{ type: 'article' }],},{type: 'string',name: 'title',title: 'Title',},{type: 'array',name: 'links',title: 'Links',of: [{ type: 'toc.link' }],},],};const tocLink = {name: 'toc.link',type: 'object',title: 'Link',preview: {select: {title: 'title',targetTitle: 'target.title',},prepare: ({ title, targetTitle }) => ({title: title || targetTitle,}),},fields: [{type: 'reference',name: 'target',title: 'Target article',to: [{ type: 'article' }],description: 'No target article turns the item into a subheading.',},{type: 'string',name: 'title',title: 'Title',description: 'Override title from the target article.',},{type: 'array',name: 'children',title: 'Children',of: [{ type: 'toc.link' }],},],};const toc = {name: 'toc',type: 'document',title: 'Table of Contents',fields: [{type: 'string',name: 'name',title: 'Name',},{type: 'string',name: 'title',title: 'Title',},{type: 'array',name: 'sections',title: 'Sections',of: [{ type: 'toc.section' }],},],};export default { tocSection, tocLink, toc };
This is a bit of code, but notice that this is also recursive, meaning that you can make sub-sections. We can also use Structure builder to query this structure and group the documents accordingly in other views, which also allows you to browse the same documents by different criteria depending on what you're doing.
This makes it very easy for us to both test and change the navigation structure if we want to. We could even A/B-test it, if we thought that was a good idea (probably not). Another nice byproduct is that since these are references, we can't outright delete an article that's put into a table of contents. So we keep content integrity even though this system doesn't “know” about its presentation.
Folders
Sanity doesn't have folders in the traditional sense, so folder like organization happens like the approach above. That being said, someone could totally make a folder tool to give people that affordance. But I'm not sure it's worth the time?
Menus or Collections
This is pretty much covered by the example above.
Tags or Categories
You can implement categories using the reference field, and you can get ad hoc tags via the string field:
// tags.jsexport default {name: 'tags',type: 'array',title: 'Tags',of: [{type: 'string'}],options: {layout: 'tags',}}
Aggregation as content model or as editor experience?
What I think it's good with the way we approach content modelling at Sanity.io is that aggregation can be done either as an implementation detail through queries, as a content model concern through references, or as a workflow mode through structure builder. And these can be done independently.
Content Rough-In
It sometimes takes a bit of actual building, and some back-n-forth to get the content model right. Preferably, you have done some prior work before diving into the technical implementation. That being said, it's so easy to iterate and test things out with the studio, that I often find myself just coding up fields while I discuss with my team how things should work. In that group there will be the ones who are actually making the presentation layer, as well as the people who will work with the content.
So although the authors explicitly state that the “rough-in” is not about migration, in my experience, if you go by a content-first approach, you'll almost always need to move some stuff around early on.
We always try to get real content into the system as early as possible. That's where the learning and the uncovering of the unknowns are. And almost always, you'll discover that you need to structure something differently or rename a field. That's where migration scripts or simply exporting your whole dataset and use find/replace-all and importing it again moves you along. Since your content comes as JSON documents, it's a cakewalk to migrate compared to SQL tables with join tables and whatnot.
Templating and Output
The authors does a decent job of exemplifying how you integrate your content using a template language. In traditional CMSs you'll get a built-in HTML rendering system, with a chosen templating language. With Sanity, the content will be available through APIs, which let you integrate with any front-end framework (and other things that's not even of the web). The approach is fairly similar though you'll have accessible “placeholders” (aka variables) that you can map out, iterate over, build logic from, and so on. The starter projects over at sanity.io/create will give you a sense of how it can be put together.
Templating languages
It's interesting that in the author‘s list of templating languages, there is a glaring lacuna: JavaScript (I guess there's a certain headless CMS blindspot here?) But common templating languages, or front-end frameworks in the JavaScript world are:
- React, and site-builders like Next.js and Gatsby.js
- Vue, and site-builders like Nuxt, Gridsome, and VuePress
- Angular, and site-builders like Scully
- Svelte, and site-builders like Sapper
- Node.js based site builders like 11ty which offer a range of templating languages
We are talking about some fairly large ecosystems here, and approaches like JAMstack, which has taken the idea of generating websites from content over APIs to the modern web.
The authors of the web project book also offer some reflections on using PHP directly to generate output (as the worlds largest CMS does, Wordpress) and why you wouldn't want to do that:
- Templating languages are “safer” in terms of not giving frontend developers powers to accidentally break the whole website
- Templating languages are usually simpler
- Generating output with full programming languages are “crude and unpleasant in most cases”
There are some sweeping generalizations here that I suspect many front-end developers would disagree with. Using JavaScript along with a templating language in React or Vue gives you both pleasant ways of building the markup, but also pleasant ways of building interactivity and managing state. Interactive user experiences is often a demand, which involves having to deal with state. Following the author‘s advice, you often have to tack that on after the fact, which can lead to breakage and messy projects as well.
If you use a modern site-builder like Gatsby, it will, in most cases, catch errors and tell you when you're rebuilding the site. And you will not be victim to closed database connections and rouge plugins typical for the CMSes that comes with built-in templating languages (yes, I know you can put caching layers onto those too).
There is no lack of testimonials of people that enjoy building the web using JavaScript, PHP (also using frameworks like Laravel), or whatnot. I don't think it's fair to say that it is “crude and unpleasant in most cases” anymore.
Other Development Tasks
Users, Groups, and Permissions
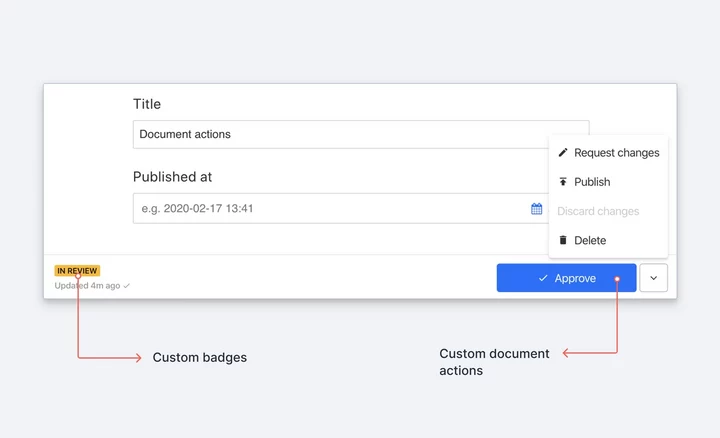
Although you can get pretty flexible access control, I prefer to emphasise trust and accountability when it comes to permissions for people who work with content. With great field description, and validation, and document actions, you can create affordances that remove bureaucracy while giving editors the safe-guards they need.
Workflows and Content Operations
Using features like Structure Builder and Document Actions you can create different groupings and sortings of your document, based on everything from what they contain to kanban flows, or even user-specific document listings.
Localization
With Sanity, localization is an aspect of content modelling, rather than its own dedicated feature. That's a bit unusual, but when you take a closer look it makes sense: It means that you're free to choose between field, document, or even dataset level localization (or a mix). It means you're able to combine personalisation (segmentation) and localization relatively easily (if you think of it, they're two sides of the same coin).
Marketing Tools
As mentioned above, you can write schemas that let you create specific content for specific groups or markets. You can use Sanity to handle routes on your website (or voice assistant or whatever), which can contain multiple versions of the same content and weights that your system for A/B-testing can use. You can also integrate with Mailchimp, Marketo, Hubspot, or Salesforce if you want to either push or pull content or data from those.
Page Composition
We tend to promote that you structure your content by not tying it to a specific presentation, but following the mental and operational models in your organization (hence, don't organize it in product pages, but as products). Hence, page composition (or layout) should be a concern of the presentation layer, in most cases, the frontend. Then again, the ability to build landing pages of different modules and content types is a frequent request. Dean and Corey remark in a footnote, that:
Dynamic page composition is exciting to see in a demo, but editorial teams usually never use it to the level they imagine they will.
I suspect that they have a point, then again, if you have a productive marketing team, chances are that you are making landing pages to improve SEO and Adwords campaigns on a fairly regular basis.
With Sanity, you can have page composition, while still keeping it fairly structured. If you build with a design system and create components and modules with a decent level of abstraction. The usual pattern is to create an array-field, and compose dedicated object types to it. You can try this simple example on sanity.io/create, where the field looks like this:
export default {name: 'content',type: 'array',title: 'Page sections',of: [{ type: 'hero' },{ type: 'imageSection' },{ type: 'mailchimp' },{ type: 'textSection' },]}
And here's the field in actions, with an example front-end.
Search, reporting, arching, integrations, and forms
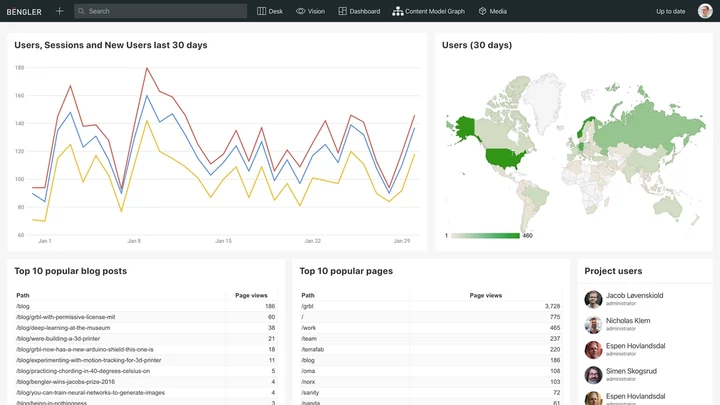
The authors also mention search, reporting, archiving, integration, and forms. With Sanity, you can choose to integrate with search services like Algolia and lets you customize search inside of the Studio. Using Structure builder you can set up lists with custom filters that let you get an overview (aka report) of unused assets, or content with publishDate from last year, or whatever you need. You can even use the Google Analytics plugin to get a list of content with a high bounce rate, in order words, actually use that data for something actionable.
Sanity keeps the patch history of your documents (like Google Docs) if you want to rewind and restore older versions. You can have an external archive by utilising the export endpoint if you prefer to delete documents, or you can add it as a boolean field and “soft delete” documents. Integrations are a huge topic, where the benefit of being real-time comes to shine: Set up services to path, augment and create content without having to deal with document locking on race-conditions.
If you need forms, you can do that too. Check out this example with Netlify, or this implementation that let's you use Sanity to also build forms that can be serialized and used in a frontend. This is the power of having versatile APIs, and being a content platform, rather than the old CMS conventions but with APIs and an webapp you can't customize as you need.
The big picture
I wholeheartly agree with Deane and Corey when they assert that “back-end and front-end implementations often run in parallel”. However, their following line isn't necessarily true longer, at leats not with Sanity: “There’s a lot that a back-end team can do before they need the front-end team’s output for templating.“
If you have empowered your frontend-team to pick modern frontend technologies, they can start building at any time. With Sanity, they will not strictly need a “back-end team” to get the content APIs they need on day 1. Your frontend developers can use the same skills as they do with the frontend. In fact, if you put your developers, your designers, and your content people together in a two hour workshop, they should be able to be working with real content with Sanity Studio, while setting up the shell implementation of the presentation layer, and start sketching out which components and modules that needs to be designed.
In other words, it's feasable to avoid having to coordinate “two teams”, but rather, have one team that works inter-displinary and focused on rapid and continous iteration. You still may need “back-end engineers” if you need to integrate with other services and back-office systems. They are usually happy because they don't need to deal with the CMS and get powerful APIs that makes their work pleasant.
And this is not just consultant speak or my content marketing. I have been part of these processes using other systems, but also Sanity. Rather, it's because this approach worke so well for me and my teams, I was happy to join Sanity.io to help other developers work better with content.